
One of my research interests has been the geographic distribution of early student achievement at the school district-level. District-level outcomes apply to large areas that are often out of alignment with neighborhoods, cities, and counties where local information could benefit parents and local governments making early education decisions. Additionally, I suspect that learning outcomes vary spatially according to a stochastic process influenced only partially by district boundaries, which in the context of multilevel modeling might appear as autocorrelation among within-group errors or as spillovers resulting from the modifiable areal unit problem. Therefore, I have begun examining sub-district geographic distributions.
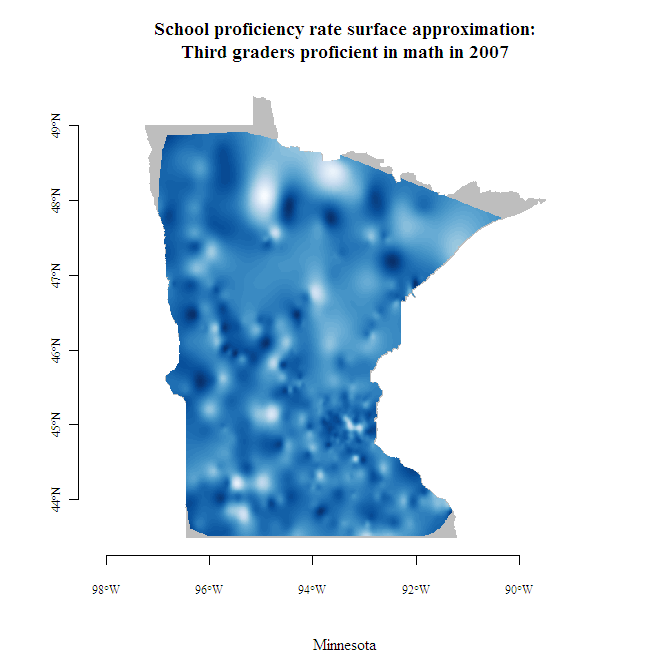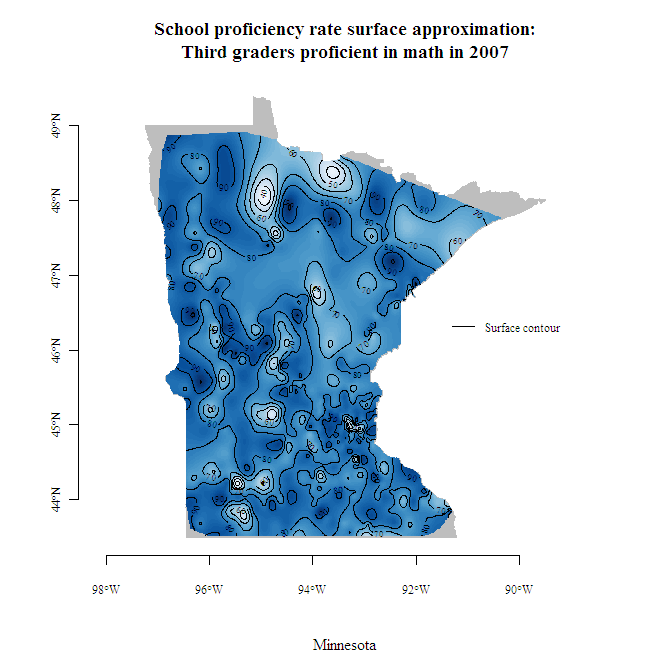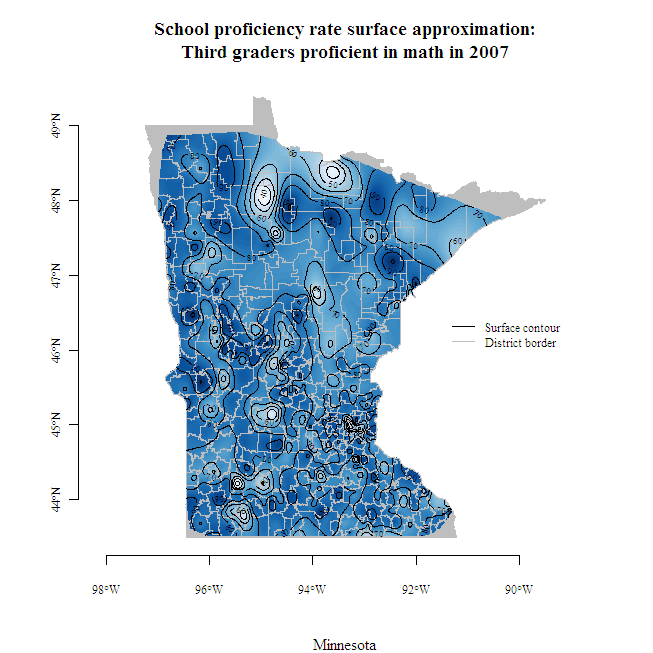
School level results go a long way towards providing local-level information, but what about early learning outcomes in between school locations, where children live? As shown in the map at right, school-level results can be used to interpolate outcomes between schools. Interpolation is the process of using known values at a set of locations to estimate unknown values at different locations. When estimating an unknown value, nearby known values are typically given more weight (i.e., made to be more influential) than distant known values. Interpolation may be thought of as a three-dimensional version of locally weighted scatterplot smoothing (LOWESS). LOWESS yields a line, while spatial interpolation yields a surface, both lacking an explicit functional form.
Click on the image to see a larger map created with the help of Finley and Banerjee’s Multilevel B-spline Approximation (MBA) package.