
Back in March I led a workshop on geographic mapping and spatial analysis with R. I finally got around to running my notes and syntax through Sweave to create a single document. Click on the image below to access the workshop notes.
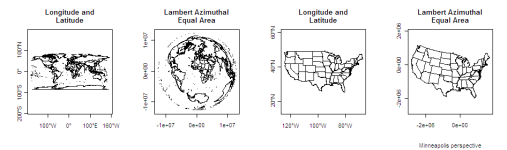
Back in March I led a workshop on geographic mapping and spatial analysis with R. I finally got around to running my notes and syntax through Sweave to create a single document. Click on the image below to access the workshop notes.
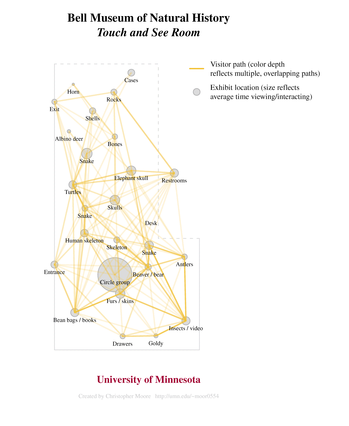
Frances Lawrenz is one of my advisors. She knew about my interest in spatially enable evaluation and put me in touch with Bob Tornberg, a graduate student in Educational Policy and Administration who was leading an evaluation for the Bell Museum of Natural History. I had been looking for an opportunity to apply mapping and/or spatial analysis to a micro-level evaluation setting, such as a classroom. Bob wanted to give the primary intended users (PIUs) of the evaluation some information about paths traveled by visitors to the museum’s Touch and See Room. Spatially enabled evaluation sounded like a mutually beneficial approach, so we decided to collaborate. I’m glad that Bob involved me before data collection began because I was able to suggest data recording procedures that later facilitated the mapping and analysis. I don’t think it would be appropriate to share the statistical results here, but I think it’s okay to share one of the maps. I think the maps turned out well, and I’m looking forward to hearing the PIUs’ impressions.
Amy and I took a fantastic day trip down the Nemadji River near Duluth. The north fork of the Nemadji River valley is wild and undeveloped compared to its sister river, the Saint Louis.

We camped the night before at Jay Cooke State Park, dropped our canoe off at the put-in on state highway 23 in Minnesota, drove our car to the take-out on county highway W in Wisconsin, and then took a taxi back to the put-in.
The river was running at about 300 cubic feet per second (cfs), which is about the minimum for an enjoyable trip and only occurs after significant rainfall. The Nemadji carries a large amount of clay sediment, making the water red and obscuring “widow-maker” rocks just below the surface.

We saw no signs of human life along the river, except for few deer stands and a couple pieces of trash. We did, however, see several mergansers, two blue herons, a hawk, and several beaver chews.
I highly recommend a trip down the north fork of the Nemadji, if you can time the river level and are willing to arrange a shuttle.
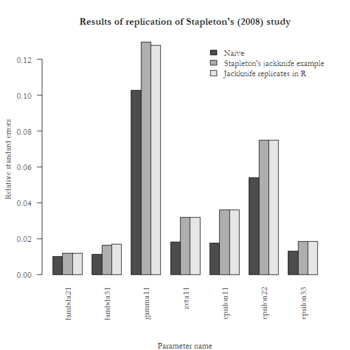
My last post demonstrated a structural equation model (SEM) of complex sample data in ![]() . I attempted to replicate Laura Stapleton’s example, but my standard errors were larger than expected.
. I attempted to replicate Laura Stapleton’s example, but my standard errors were larger than expected.
I wrote to Laura, and she graciously reviewed my results. She attributed the standard error discrepancies to a change in IRT score variances. Specifically, the ECLS-K math and reading scores have been re-scaled since the original data set was published, resulting in larger variances in the currently published version. She supplied me with her version of the original public-use data set.
The updated results with the original data set are nearly identical to her published results. I feel confident now about using ECLS-B jackknife replicate weights for SEM in ![]() , and I learned a lot from attempting the replication.
, and I learned a lot from attempting the replication.
Path diagram of U.S. kindergartners’ cognitive achievement (indicated by reading, math, and general ability scores) regressed on number of residences in last four months
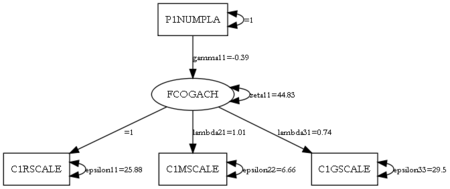
I am using data from the Early Childhood Longitudinal Study (ECLS) Birth Cohort for my research assistantship with Judy Temple. I have an analysis in mind that will involve factor analysis and path analysis simultaneously (i.e., a structural equation model).
The ECLS-B data and other large microdata sets represent the population, offer good statistical power, and provide comprehensive measures, making them suitable for structural equation modeling. However, those advantages are often achieved through stratified cluster sampling, which nests participants within primary sampling units in order to ensure adequate representation of strata and hold down data collection costs. Moreover, individuals representing small groups in the population are oversampled, which requires analytically re-weighting those cases downward to reflect population proportions but not down-weighting sample sizes in the standard error calculations. Calculating standard errors under complex sampling conditions is not straightforward compared to simple random sampling.
Is it possible to fit structural equation models of complex sample data in ![]() ? Several statistical software programs, including the survey package, can perform standard analyses (e.g., means, generalized linear models) in a manner appropriate for complex sample data. However, hardly any programs offer the ability to fit structural equation models to such data. Using some guidance offered by John Fox, author of the sem package, and an excellent article by Laura Stapleton, I decided to give it a try with R.
? Several statistical software programs, including the survey package, can perform standard analyses (e.g., means, generalized linear models) in a manner appropriate for complex sample data. However, hardly any programs offer the ability to fit structural equation models to such data. Using some guidance offered by John Fox, author of the sem package, and an excellent article by Laura Stapleton, I decided to give it a try with R.
Stapleton used data from the ECLS Kindergarten Cohort and two commercial statistical software packages to demonstrate a structural equation model that applies sampling weights and accounts for multistage sampling. Because the ECLS-K is publicly available and ![]() is free, I was able to attempt her jackknife example. As hoped, the replication yielded parameter estimates that were comparable to Stapelton’s, as well as standard errors that were larger than the naive standard errors. However, my jackknife standard errors were consistently larger than Stapleton’s. I don’t yet know why they were so large, but it will be good practice for me to find out. It will also be good practice to replicate her example of bootstrapping standard errors. I welcome any feedback about this approach.
is free, I was able to attempt her jackknife example. As hoped, the replication yielded parameter estimates that were comparable to Stapelton’s, as well as standard errors that were larger than the naive standard errors. However, my jackknife standard errors were consistently larger than Stapleton’s. I don’t yet know why they were so large, but it will be good practice for me to find out. It will also be good practice to replicate her example of bootstrapping standard errors. I welcome any feedback about this approach.